

تغییر نگرش به «برچسب» و تحول در یادگیری ماشین
تغییر نگرشهای منجر به رشد سریع هوش مصنوعی مولد در سالهای اخیر (۱)
در سالهای اخیر، «هوش مصنوعی مولد» و «مدلهای زبانی» [1] با رشدی بیسابقه و ناگهانی به یکی از حوزههای پرطرفدار و پرکاربرد در امور روزمره، علوم کامپیوتر و توسعه کسبوکار تبدیل شده است. این پدیده که میتوان آن را یکی از مهمترین تحولات در هوش مصنوعی در نظر گرفت، محصول به هم پیوستن مجموعهای از ایدههاست که در حوزههای مختلف علوم کامپیوتر به کار گرفته شده و مراحل رشد و تحول خود را طی کردهاند. در مجموعه «تغییر نگرشهای مولد: نگاهی به تحولات هوش مصنوعی» تلاش خواهیم کرد به ایدههای اساسی و نقاط عطفی که منجر به پیدایش و توسعه گونههای جدید هوش مصنوعی شده بپردازیم.
«هوش مصنوعی مولد» شاخهای از هوش مصنوعی است که بر نوع خاصی از به کارگیری ایده «یادگیری ماشین»[2] بنا شده است. آموزش یادگیری ماشین کتابها و درسهای دانشگاهی معمولا با یک تقسیمبندی حول مقوله «دادۀ برچسبخورده» آغاز میشود: یادگیری بانظارت[3]، یادگیری بدوننظارت[4] و پس از آنها یادگیری تقویتی[5]؛ اما آنچه باعث رشد و توسعه ناگهانی هوش مصنوعی مولد شده، بازی با این تقسیمبندی کلاسیک و خلاقیت در تلفیق آنها با یکدیگر و ارائه یک چهارچوب جدید است.
برای اینکه بفهمیم فراتر رفتن از تقسیمبندی حول «داده برچسبخورده» چگونه منجر به تحولات جدیدی در یادگیری ماشین شده، بهتر است ابتدا این سه رویکرد را به اختصار مرور کنیم.
یادگیری بانظارت
در یادگیری بانظارت سعی میکنیم با استفاده از دادههای برچسبخورده توسط یک ناظر، مدلی ایجاد کنیم که برچسب دادههای جدید را با دقت قابل قبولی حدس بزند. ناظر کسی است که به دادهها برچسب میزند تا ماشین برچسب زدن به دادهها را از روی دست او یاد بگیرد.
مثال معروف یادگیری بانظارت، شناسایی ایمیلهای تبلیغاتی یا هرزنامه[6] و جداکردن آن از ایمیلهای واقعی[7] است که کاربر در صندوق نامههای الکترونیک خود دریافت میکند. در اینجا دو برچسبِ «هرزنامه» یا «واقعی» از پیش تعریف شده و مدل با استفاده از تعداد قابل توجهی از ایمیلهای برچسبخورده آموزش داده میشود تا هرزنامه یا واقعی بودن ایمیلهای جدید را با توجه به شباهت آنها به ایمیلهای برچسبخورده پیشبینی[8] کند. هر بار که کاربر نتیجه پیشبینی مدل را اصلاح میکند و ایمیلی را از حالت هرزنامه خارج میکند، ماشین از داده جدید یاد میگیرد تا در آینده پیشبینیهای بهتری برای هرزنامه یا واقعی بودن ایمیلهای هر کاربر ارائه کند.
{kind=link}
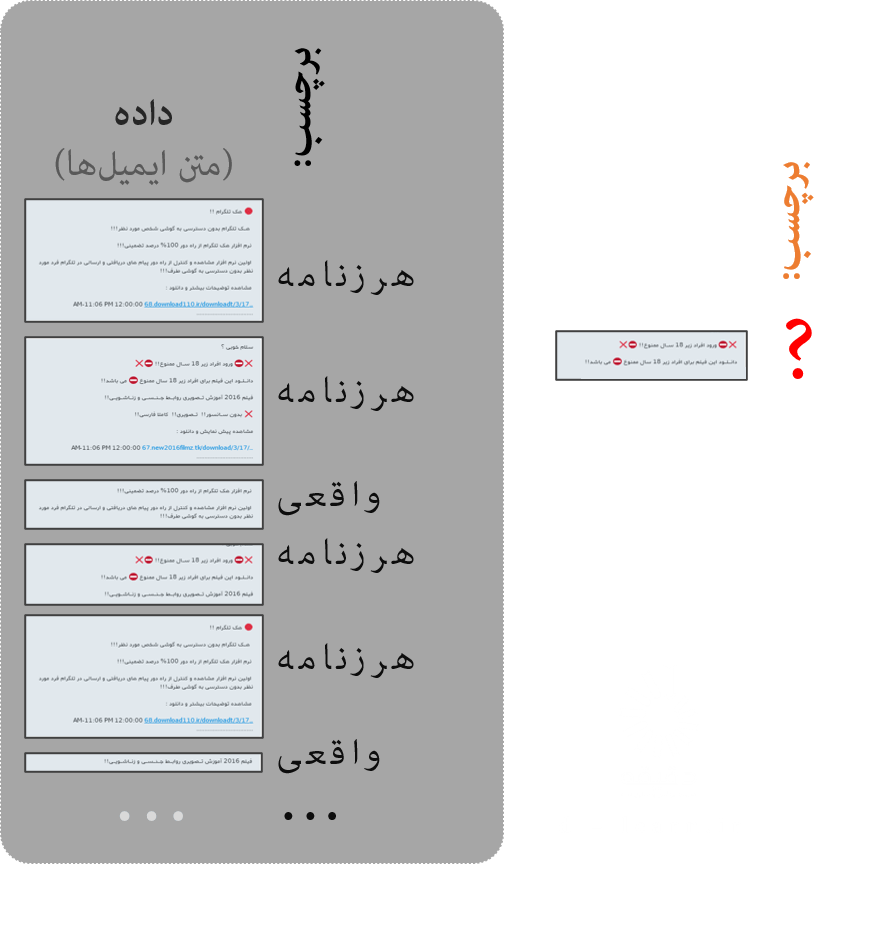{kind=link}
مثال معروف دیگر تشخیص برچسب احساسی جمله در سه دسته «مثبت»، «خنثی» و «منفی» است برای اینکه ماشین بتواند احساسات پنهان در جملات جدید را حدس بزند. به این کار در پردازش متن، اصطلاحاً تحلیل احساسات[9] گفته میشود.
نمونه معروف دیگر برای یادگیری بانظارت، مدلهای پیشبینی قیمت بر اساس دادههای گذشته است[10]. مثلا اگر دادههای معاملات مسکن در یک شهر را داشته باشیم میتوانیم تخمینی ارزشمند از قیمت یک معامله جدید در آن به دست بیاوریم و اصطلاحا قیمت آن را پیشبینی کنیم. در مسئله پیشبینی تلاش میکنیم تا یک ویژگی مثل قیمت را بر اساس ویژگیهای دیگری مثل طول و عرض جغرافیایی، مساحت، سن بنا، پارکینگ داشتن یا نداشتن، آسانسور داشتن یا نداشتن، انباری داشتن یا نداشتن و … پیشبینی کنیم. به دادههای زیر نگاه کنید.
شماره مشاهده | طول جغرافیایی | عرض جغرافیایی | مساحت | سن | نوع اسکلت | پارکینگ | انباری | آسانسور | قیمت هر متر مربع |
معامله 1 | 35.6851 | 51.3704 | 120 | 9 | فلزی | 1 | 0 | 1 | 48 |
معامله 2 | 35.6334 | 51.3211 | 65 | 27 | بتونی | 1 | 0 | 0 | 67 |
معامله 3 | 35.6572 | 51.3315 | 93 | 16 | فلزی | 0 | 1 | 1 | 118 |
… | … | … | … | … | … | … | … | … | … |
در این دادهها تعدادی مشاهده از معاملات انجام شدۀ شهر به عنوان داده برچسبخورده گردآوری شده است. در رویکرد یادگیری بانظارت از این دادهها برای توسعه مدلهای پیشبینی استفاده میشود. یک مدل پیشبینی میتواند ساده و قابل تفسیر یا پیچیده و غیر قابل تفسیر باشد و نتوان به راحتی از منطق و محاسبات آن سر در آورد. وظیفه چنین مدلهایی پیشبینی ویژگی مورد نظر مثل قیمت برای مشاهدات جدید است.
شماره مشاهده | طول جغرافیایی | عرض جغرافیایی | مساحت | سن | نوع اسکلت | پارکینگ | انباری | آسانسور | قیمت هر متر مربع |
معامله جدید | 35.6137 | 51.3217 | 106 | 19 | فلزی | 1 | 1 | 1 | ؟؟؟ |
 1")
مسائل پیشبینی اغلب در چهارچوب یادگیری بانظارت مورد بحث و بررسی قرار میگیرند.
یادگیری بدوننظارت
در یادگیری بدون نظارت، برخلاف رویکرد یادگیری بانظارت، برچسبهای از پیش تعریف شده یا دادۀ برچسبخورده برای پیشبینی وجود ندارد. در رویکرد بدون نظارت دادهها پردازش و تحلیل میشوند تا قواعد و الگوهای پنهانی مثل شباهتها و تفاوتهای مشاهدات با یکدیگر کشف شود. یکی از مثالهای معروف یادگیری بدون نظارت، خوشهبندی[11] است؛ مثل خوشهبندی مشتریان[12] که طراحی استراتژیهای مناسب برای طراحی محصولات جدید و توسعه بازار کاربرد دارد. در خوشهبندی مشتریان، تعداد گروههای از پیش تعیینشدهای برای شناسایی وجود ندارد، اما تفکیک مشتریان به گروههای متمایزِ تشکیلشده از افراد شبیه به یکدیگر بسیار سودمند است، چرا که مدیریت در مییابد که با چند گونه مشتری طرف است و میتواند استراتژی خود را متناسب با آن طراحی کند.
به عنوان نمونه در میان مشتریانِ یک سوپر مارکت، گروههای مختلف مشتریان بر اساس فاکتورهای خریدشان میتواند شامل چهار خوشه متمایز باشد: (1) کسانی که مواد شوینده میخرند، (2) کسانی که بیسکوییت، تنقلات و نوشیدنی میخرند، (3) کسانی که نوشابه، تخم مرغ، غذاهای یخزده و کنسروی میخرند و (4) کسانی که اغلب لبنیات، تخم مرغ، گوشت و مرغ میخرند. دادههای این مسئله کموبیش چنین شکل و شمایلی دارد:
شماره مشاهده | شیر | پنیر | ماست | تخم مرغ | تن ماهی | مرغ | گوشت | مایع ظرفشویی | … |
مشتری 1 | 1 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | … |
مشتری 2 | 0 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | … |
مشتری 3 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 1 | … |
… | … | … | … | … | … | … | … | … | … |
اگر در این مسئله خرید هر یک از اقلام فوق را یک ویژگی و هر مشتری را به عنوان یک مشاهده در نظر بگیریم، هدف نه پیشبینی یک ویژگی بر اساس ویژگیهای دیگر بلکه شناسایی مشاهدات شبیه به یکدیگر با توجه به ویژگیهای مشترک آنها است.
 2")
مثال دیگر گروهبندی موضوعی مقالات[13] و قرار دادن آنها در گروههای جداگانه است. به نظر شما برای حل این مسئله، «ویژگی» را در مقالات چگونه میتوان تعریف کرد؟
یادگیری تقویتی
در یادگیری تقویتی نیز داده برچسبخورده برای محاسبه میزان دقت یا درستیِ حدسها در مراحل میانی وجود ندارد، اما یک برچسب نهایی از جنس «پاداش» یا «مجازات» وجود دارد تا به مرور ماشین بر اساس آن به الگوهای پیروز پرداخته و به این ترتیب یادگیری خود را تقویت کند. یکی از کاربردهای یادگیری تقویتی، استفاده از بازیهای پیچیدهای مثل شطرنج است. فرض کنید دادههای زیادی از بازیهای شطرنج در اختیار داریم و میخواهیم برنامهای بنویسیم تا کامپیوتر بتواند به خوبیِ یک استادبزرگ شطرنج بازی کند. در این دادهها برای هر حرکت به تنهایی ارزشگذاری مشخصی در طول بازی وجود ندارد، اما برای هر بازی در انتها یک برچسب «برد» یا «باخت» وجود دارد. رویکرد یادگیری تقویتی تلاش میکند تا مجموعه عظیم دادههای بدون برچسب شامل حرکتهای مختلف و پاسخی را که از محیط دریافت میشود، با استفاده از همین یک برچسب یعنی پیروزی و شکست پردازش و تحلیل کند تا ماشین به استراتژیهای پیروز دست یابد.
نمونههای دیگر از کاربرد یادگیری تقویتی را میتوان در سیستمهای توصیهگر[14] فروشگاههای آنلاین و بهینهسازی سبدهای سرمایهگذاری[15] در بازار سهام به خوبی مشاهده کرد.
گذار به یک رویکرد جدید
مدلهای بدون نظارت معمولا نیازمند تنظیم پارامترهای مختلف مسئله مثل تعداد معنادار خوشهها و تفسیر هستند. این تنظیم در بسیاری موارد توسط انسان متخصص انجام میشود و در برخی موارد به اطلاعات بیرونی برای تصمیمگیری مناسب نیاز دارد. به همین خاطر میتواند کُند و پرهزینه باشد. این مسئله به دلیل دسترسی به داده برچسبخورده در مدلهای تحت نظارت وجود ندارد و کل فرایند به صورت خودکار و بدون مداخله عامل انسانی انجام میشود. آنچه در مدل تحت نظارت به وسیله ناظر انسانی انجام میشود، برچسب زدن دادههاست. اما برچسب زدن توسط ناظر انسانی در مقیاس بزرگ بسیار هزینهبر است. در یک دوره زمانی، شرکتهای بزرگ برای اینکه دادههای خود را برچسب بزنند به ترفندهایی مانند جمعسپاری در قالب پر کردن جای خالی در عبارات کپچا[16]یا پیدا کردن سگ و گربه و اتوبوس در تصویر روی آوردند. این نیاز وقتی برای برچسبزدن دادهها به نیروی انسانی متخصص با سطح دانش بالا مثل پزشک، دندانپزشک و رادیولوژیست نیاز است بسیار پرهزینهتر نیز میشود.
یادگیری خودنظارتگر
نیاز گسترده و البته پرهزینه به عامل انسانی برای برچسبزدن دادهها و ایجاد مدلهای بانظارت با تغییر نگرش به تقسیمبندی کلاسیکِ یادگیریِ بانظارت و بدوننظارت در سالهای اخیر فروکش کرد و دنیای یادگیری ماشین با یک رویکرد جدید در مواجهه خود با دادههای برچسبخورده روبرو شد. به این رویکرد جدید یادگیریِ خودنظارتگر[17] گفته میشود. این رویکرد تلاش میکند تا با ترفندهای مختلف از دادههای بدون برچسب، دادۀ برچسبخورده تولید کند و به این ترتیب مشاهدات جدیدی برای یادگیری ماشین به وجود بیاورد.
پردازش متن و مدلسازیهای زبانی
یادگیری خودنظارتگر تلاش میکند تا بر اساس چند ایده جالب و در عین حال ساده و سرراست داده برچسبخورده تولید کند و سپس از آنها برای مدلسازی بانظارت استفاده کند. در ادامه با بررسی چند نمونه در حوزه پردازش زبان با برخی از این ایدهها آشنا میشویم. خاستگاه تحولات جدید هوش مصنوعی در حوزه پردازش دادههای زبانی و اطلاعات متنی است.
ایده پوشاندن
یکی از ایدههای اصلی در یادگیری «خودنظارتگر»، پوشاندن بخشهایی از داده برای تولید دادۀ برچسبخورده به عنوان مشاهدات جدید است. ایده پوشاندن[18] در ایجاد مدلهای زبانی و پردازش تصویر کاربرد زیادی دارد. برای اینکه بیشتر با ایده پوشاندن آشنا شویم، به یک مثال از دادههای زبانی توجه کنید.
فرض کنید تعداد زیادی جمله به زبان فارسی گردآوری کردهایم و میخواهیم با استفاده از این دادهها یک مدل یادگیری ماشین برای توسعه یک چتبات برای تولید متن و پاسخ به پرسشهای کاربران فارسیزبان ایجاد کنیم. تصور کنید یکی از این جملات به این صورت است:
- عدالت آموزشی در دنیا همچنان با چالشهای زیادی مثل فقر و تبعیض جنسیتی مواجه است.
این یک داده بدون برچسب است، اما با پوشاندن بخشهای مختلف آن میتوانیم داده برچسبخورده مثل موارد زیر ایجاد کنیم. به عنوان مثال به موارد زیر توجه کنید:
- عدالت آموزشی در دنیا همچنان با ……….. زیادی مثل فقر و تبعیض جنسیتی مواجه است.
برچسب این داده همان عبارت پوشاندهشده یعنی «چالشهای» است. این روش میتواند دادههای برچسبخورده زیادی از دادههای متنی تولید کند. مدل برآمده از این دادهها جاهای خالی در جملات و عبارات را پیشبینی کند و عبارتهای جدیدی برای درج در آنها پیشنهاد دهد.
پیشبینی عبارت بعدی
اگر جای خالی یا بخشهای پوشاندهشده را در آخر متن قرار دهیم، مدل ما از یک قابلیت ویژه و هیجانانگیز برخوردار میشود و آن چیزی نیست غیر از پیشبینی کلمه بعدی[19]. این ایده همان چیزی است که پای مدلهای پیشبینی و یادگیری بانظارت را به تولید محتوای متنی باز کرده است: اگر مجموعهای از عبارات را یکی پس از دیگری به مدل بدهیم، محتملترین عبارتی که میتواند برای بعد از آن پیشنهاد شود چیست؟
اگر جمله یادشده را به عنوان تنها داده در نظر بگیریم، این مسئله به صورت زیر حل میشود:
- عدالت …………
- عدالت آموزشی …………
- عدالت آموزشی در …………
- عدالت آموزشی در دنیا …………
- عدالت آموزشی در دنیا همچنان …………
- عدالت آموزشی در دنیا همچنان با …………
- عدالت آموزشی در دنیا همچنان با چالشهای …………
- …
 3")
ایدۀ پیشنهاد کلمه بعدی هنگام تایپ در برنامههای مختلف کامپیوتری مثل موتورهای جستجو و ایمیل در گذشته نیز سابقه دارد، اما در سالهای اخیر با تحولی عظیم در مدلهای جدید هوش مصنوعی همراه شده است.
قدم نخست این ایده تولید دادههای برچسبخوردهای مثل مشاهدات جدول زیر است که بدون نیاز به ناظر از دادههای متنی استخراج میشوند.
شماره مشاهده | مقدارهای ورودی | برچسب |
1 | عدالت آموزشی در دنیا همچنان با چالشهای زیادی مثل فقر و تبعیض جنسیتی مواجه | است |
2 | عدالت آموزشی در دنیا همچنان با چالشهای زیادی مثل فقر و تبعیض جنسیتی | مواجه |
3 | عدالت آموزشی در دنیا همچنان با چالشهای زیادی مثل فقر و تبعیض | جنسیتی |
4 | عدالت آموزشی در دنیا همچنان با چالشهای زیادی مثل فقر و | تبعیض |
5 | عدالت آموزشی در دنیا همچنان با چالشهای زیادی مثل فقر | و |
6 | عدالت آموزشی در دنیا همچنان با چالشهای زیادی مثل | فقر |
7 | عدالت آموزشی در دنیا همچنان با چالشهای زیادی | مثل |
… | … | … |
ایده پیشبینی عبارت بعدی علاوه بر کلمات، برای جملات نیز پیادهسازی میشود و از آن با عنوان پیشبینی جمله بعدی[20] یاد میشود.
ایده به هم زدن ترتیب
شماره مشاهده | مقدارهای ورودی | برچسب |
1 | همچنان با چالشهای عدالت آموزشی در دنیا زیادی جنسیتی مواجه است مثل فقر و تبعیض | عدالت آموزشی در دنیا همچنان با چالشهای زیادی مثل فقر و تبعیض جنسیتی مواجه است |
2 | چالشهای آموزشی در همچنان با جنسیتی مواجه است مثل فقر و تبعیض عدالت دنیا زیادی | عدالت آموزشی در دنیا همچنان با چالشهای زیادی مثل فقر و تبعیض جنسیتی مواجه است |
3 | آموزشی در همچنان با چالشهای جنسیتی مواجه است مثل فقر و عدالت دنیا زیادی تبعیض | عدالت آموزشی در دنیا همچنان با چالشهای زیادی مثل فقر و تبعیض جنسیتی مواجه است |
… | … | … |
ایده دیگری که در رویکرد خودنظارتگر کابرد دارد، به هم زدن ترتیب[21] برای تولید داده برچسب خورده است. در این ایده جمله اصلی را به عنوان برچسب و ترتیب متفاوتی از کلمات تشکیلدهنده آن را به عنوان دادههای جدید در نظر میگیریم.
مدل برآمده از این ایده قادر خواهد بود تا ایرادات نحوی جملات را اصلاح کند و کلمات را در جایگاه درست آنها قرار دهد؛ مثلا فاعل را به ابتدا و فعل را به انتهای جمله ببرد. این نوع مدلسازی پیشتر در برنامههای غلطیاب و ویرایشگرها مورد استفاده قرار گرفته است.
ایدۀ یادگیری با به هم زدن ترتیب[22] به همان صورت که در مورد کلمات در جمله استفاده میشود، در مورد جملات در متن نیز کاربرد دارد.
سایر ایدهها
پوشاندن و به هم زدن ترتیب تنها ایدههای رویکردهای یادگیری خودنظارتگر نیستند. از جمله ایدههای دیگری که در این رویکرد مورد استفاده قرار میگیرد، میتوان به مدلهای پیشبینی ویژگیهای معنایی اشاره کرد.
مدلهای پردازش تصویر
ایدههای یادگیری تحت نظارت خود، کموبیش به همان صورت که روی دادههای زبانی پیادهسازی شد، در پردازش تصویر نیز قابل استفاده است. فرض کنید تعداد زیادی تصویر از جمله تصویر زیر را در اختیار داریم.
 4")
با پوشاندن بخشهای مختلف عکس و به هم زدن ترتیب قطعات آن میتوان مشاهدات جدیدی به وجود آورد و از آنها در مدلسازی برای پردازش تصویر استفاده کرد. در مدلسازی برای پردازش تصویر علاوه بر ایده پوشاندن و جابجایی اجزا، از تغییرِ اندازه و دورانِ تصویر نیز برای تولید مشاهدات جدید استفاده میشود.
{kind=link}
{kind=link}
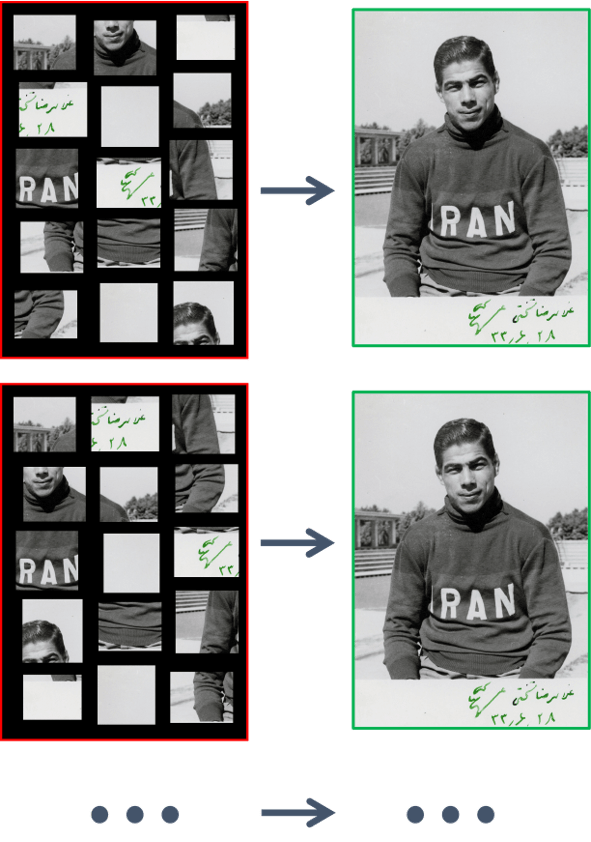{kind=link}
با این ایدهها مدلهای پردازش تصویر میتوانند رنگها و بافتهای مشابه را در کنار یکدیگر قرار دهند و موجودیتهای مختلف درون تصویر را بدون دسترسی به تصاویر برچسبخورده شناسایی کنند و بخشهای حذفشده تصاویر جدید را پیشبینی یا ایجاد کنند.
مرور و جمعبندی
یادگیری ماشین شاخهای از علوم کامپیوتر و هوش مصنوعی است که چندین دهه از تولد آن در این حوزه میگذرد. اما سالهای اخیر به موتور محرک هوش مصنوعی تبدیل شده و آن را با تحولات بیسابقهای مواجه کرده است. بخشی از این تحولات نتیجه تغییر نگرش به مفهوم به ظاهر پیش پا افتادۀ برچسب و ارائه چهارچوبی جدید در میان رویکردهای کلاسیک یادگیری ماشین است. البته این رویکرد جدید و محصولات مبتنی بر آن به هیچ رو بیهزینه نیست. یادگیری خودنظارتگر برخلاف بسیاری از روشهای پیشین، به پردازش حجم بسیار زیادی از دادهها نیاز دارد. اینکه پردازش عظیم داده در سالهای اخیر چگونه ممکن شده خود نتیجه تغییر نگرش جذاب و آموزندۀ دیگری در حوزه سختافزار است که به آن خواهیم پرداخت.
به نظر شما چه عوامل و تغییر نگرشهایی به رشد سریع هوش مصنوعی در سالهای اخیر منجر شده ؟
پاورقی و ارجاع
[1] Generative Artificial Intelligence (Generative AI) & Language Models
[2] Machine Learning
[3] Supervised Learning
[4] Unsupervised Learning
[5] Reinforcement Learning
[6] Spam
[7] Not Spam
[8] Prediction
[9] Sentiment Analysis
[10] وقتی برچسب از نوع غیرعددی یا رستهای باشد با یک مسئله پیشبینی از نوع دستهبندی (Classification) و وقتی برچسب از نوع عددی پیوسته باشد اصطلاحا با یک مسئله پیشبینی از نوع رگرسیون (Regression) مواجهیم.
[11] Clustering
[12] Customer Segmentation
[13] Topic Modeling
[14] Recommender System
[15] Portfolio Optimization
[16] CAPTCHA: Completely Automated Public Turing test to tell Computers and Human Apart
کپچا سوالی است که برای جلوگیری از نفوذ ماشین به برنامههای کامپیوتری به جای کاربر انسانی پرسیده میشود. در این سوال برنامه کامپیوتری از کاربر میپرسد تا بر اساس پاسخ آن مطمئن شود کاربر ماشین نیست و از این طریق از نفوذ امنیتی به برنامه جلوگیری کند. کلمه کپچا از حروف اول « آزمون همگانی کاملاً خودکارشدهٔ تورینگ برای تمییز دادن انسان و رایانه» گرفته شده است.
[17] Self-Supervised Learning
[18] Masking
[19] Next Word Prediction
[20] Next Sentence Prediction
[21] Permutation / Shuffling
[22] Permutation-based Training
3 پاسخ
زمانی که من دانشگاه درس داده کاوی و یادگیری ماشین گذروندم به ما فقط یادگیری باناظر و بدون نظارت را یاد دادند. وقتی با یادگیری تقویتی آشنا شدم خیلی به نظرم ابتکار جذاب و جریان سازی آمد و فکر می کردم خیلی رشد کنه اما الان self-supervised learning یادگیری ماشین زیر و رو کرده.
خیلی جالب بود.
دست شما درد نکنه.
خیلی ممنون
مدتی بود دنبال چنین مطلبی بودم تا از داستان سر در بیارم
بسیار آموزنده بود
بسیار عالی، با لحنی ساده و قابل فهم