
فهرست
وقتی میخواهیم با تکیه بر مجموعهای از داده و مشاهده به موضوعی بپردازیم یا به پرسشی پاسخ دهیم ممکن است در ابتدا هیچ دادهای در اختیار نداشته باشیم. در چنین شرایطی لازم است در اولین گام دادهها و اطلاعات مورد نظرمان را گردآوری و به نحو مطلوب سازماندهی کنیم. پرسش مهمی که در تمامی پروژه تحلیل داده وجود دارد این است که داده را در چه اشکالی سازماندهی کنم تا بیشترین کارایی را برای پردازش و تحلیل داشته باشد.
این سوال از نظر عملیاتی برای تحلیل داده یک سوال کلیدی به حساب میآید، چون به تحلیلگر ذهنیت روشنی میدهد که از کجا باید شروع کند.
عامل انسانی در اولویت
در علوم کامپیوتر در بحث «ساختمان دادهها» پاسخهای مشخصی برای این سوال وجود دارد. این پاسخها عموما ناظر بر بهینه کردن حجم پردازش و زمان آن است. اگر بخواهیم زمان تحلیلگر که یک عامل انسانی است را در نظر بگیریم موضوع کمی تفاوت پیدا میکند. برای اینکه کار با دادهها را برای تحلیلگر راحت و کارآمد کنیم باید از قالبهای ساده و استانداردی استفاده کنیم که تحلیلگر بتواند با صرف کمترین زمان از دادهها سر در بیاورد، حتی اگر بار حافظه یا حجم پردازشی که برای کامپیوتر ایجاد میشود افزایش یابد و از حالت بهینه خارج شود. این امر در دیتاژورنالیسم اهمیت بیشتری نیز پیدا میکند، چون موتور محرک آن بیشتر از آن که کامپیوتر و امکانات پردازشی آن باشد، در حقیقت همان عامل انسانی یا به عبارت دقیقتر تحلیلگر داده است. با این حال، باید از ساختارهایی برای مدیریت دادهها استفاده کرد که پردازش و تحلیل دادهها با استفاده از کامپیوتر نه تنها امکانپذیر بلکه به راحتی قابل انجام باشد.
قالب جدول
برای سازماندهی دادهها با هدف پردازش و تحلیل، روشها و قالبهای مختلفی وجود دارد. یکی از پرطرفدارترین آنها قالبِ جدول است. در این درس به معرفی قالب جدول و روشهای استاندارد سازماندهی دادهها در یک جدول پرداخته میشود.
پرطرفدار بودن قالب جدول و استانداردهای آن، نیز به خودی خود موضوعیت دارد، چرا که داده بین تحلیلگران زیاد دستبهدست میشود. به همین دلیل استفاده از استانداردهایی که جامعه کاربران بزرگتری دارد با ایجاد همافزایی، سرعت کار تحلیلگر و کیفیت کار تحلیل داده را به صورت عمومی افزایش میدهد.
روشهای گردآوری دادهها و سازماندهی دادهها در قالب جدول با ارائه چند مثال توضیح داده خواهد شد.
بررسی وضعیت سلامت
فرض کنید به خاطر وضعیت آلودگی هوا کمی نسبت به وضعیت سلامت خود حساس شدهاید و میخواهید ببینید برخی شاخصهای سلامتتان مانند هموگلوبین، تعداد گلبولهای سفید، تعداد گلبولهای قرمز، کلسترول خوب و کلسترول بد در سالهای اخیر چگونه تغییر کردهاند. برای این کار نتایج آزمایش خونی که در سالهای اخیر از آزمایشگاههای مختلف دارید را جمع آوری میکنید و اعداد مربوطه را از آنها استخراج میکنید تا در یک جدول وارد کنید.

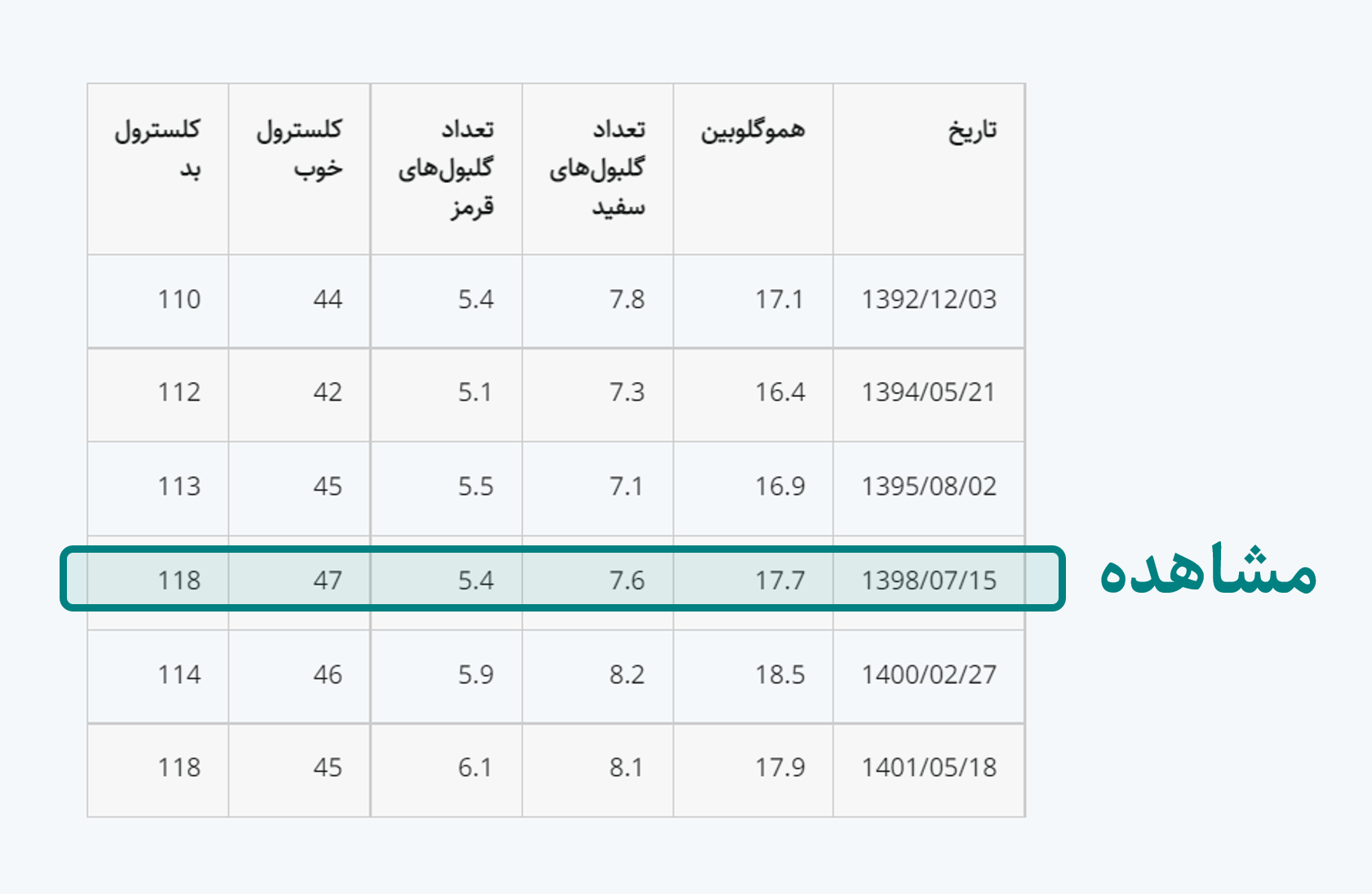
یک روش مناسب برای ذخیره این دادهها در یک جدول این است که مجموعه دادههای هر آزمایش را در یک سطر مجزا بیاوریم. به جدول زیر نگاه کنید:
| تاریخ | هموگلوبین | تعداد گلبولهای سفید | تعداد گلبولهای قرمز | کلسترول خوب | کلسترول بد |
| 1392/12/03 | 17.1 | 7.8 | 5.4 | 44 | 110 |
| 1394/05/21 | 16.4 | 7.3 | 5.1 | 42 | 112 |
| 1395/08/02 | 16.9 | 7.1 | 5.5 | 45 | 113 |
| 1398/07/15 | 17.7 | 7.6 | 5.4 | 47 | 118 |
| 1400/02/27 | 18.5 | 8.2 | 5.9 | 46 | 114 |
| 1401/05/18 | 17.9 | 8.1 | 6.1 | 45 | 118 |
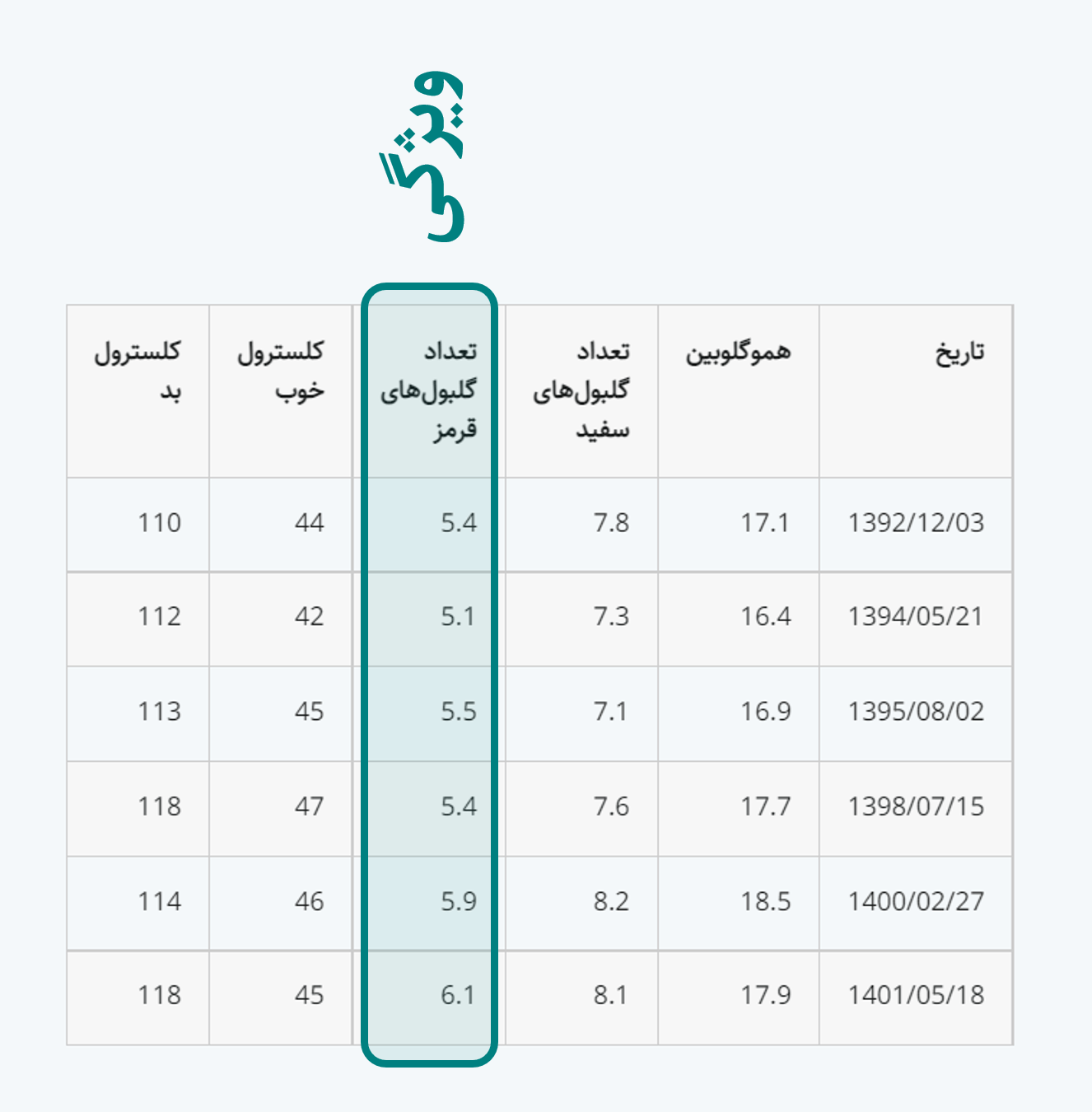
در این ساختار، آرایش آنها به گونهای است که هر سطر نشاندهندۀ یک مشاهده، هر ستون نشاندهندۀ یک متغیر و هر خانه از جدول نشاندهندۀ تنها یک مقدار است.
سطر: مشاهده
هر یک از سطرها در جدول بالا، معرّف مقادیر مربوط به نتایج یکی از آزمایشهاست که اصطلاحاً به هر یک از آنها یک مشاهده (Observation) گفته میشود. مشاهدهها با استفاده از یکدیگر قابل محاسبه نیستند؛ مثلا اگر مقدار متوسط شاخصها در تمامی آزمایشها را در یک سطر به انتهای جدول اضافه کنیم، این سطر دیگر یک مشاهده قلمداد نمیشود چون با استفاده از دیگر سطرها میتوان مقدار آن را تعیین کرد.
ستون: ویژگی (متغیر)
اگر سطرهای جدول نشانگرِ یک مشاهده باشند، میتوانیم هر یک از ستونهای آن را از نقطهنظر آماری یک ویژگی (Feature) قلمداد کنیم. ستون تاریخ در اینجا حکم شناسه مشاهدات را دارد و آنها را از یکدیگر متمایز میکند و میتوان آن را به عنوان نام مشاهدات در نظر گرفت نه یک متغیر یا ویژگی.
{kind=link}
{kind=link}
مقدارهایی که در هر یک از ستونها آمده همگی از یک جنس هستند یعنی همه به یک پدیده اشاره میکنند به همین دلیل به آن متغیر (Variable) نیز میگویند، اما مقدارهایی که در هر یک از سطرها میآیند این گونه نیستند و به شاخصهای متنوعی اشاره میکنند. اگر به کوچکی و بزرگی اعداد نیز نگاه کنید نیز اعداد داخل هر یک از ستونها از نظر بزرگی و کوچکی کم و بیش به یکدیگر نزدیکند اما اعداد درجشده در هر یک از سطرها ممکن است تفاوت زیادی با یکدیگر داشته باشند، چراکه به شاخصهای مختلفی اشاره میکنند.
در این روش سازماندهی دادهها، هیچ دو خانهای با یکدیگر ادغام (merge) نمیشود و جدول ساختاری ساده شبیه به یک ماتریس دارد تا هر خانه تنها با صدا کردن سطر و ستون آن قابل فراخوانی باشد. ادغام خانههای جدول با یکدیگر تنها زمانی کاربرد دارد که هیچ هدفی غیر از ارائه بصری جدول یا چاپ آن نداشته باشیم.
ساختار عرضی (Wide Format)
به ساختار ذخیرهسازی داده در جدول اصطلاحاً ساختار عرضی نیز میگویند. وقتی دادهها را در یک جدول با ساختار عرضی سازماندهی میکنیم، جدول با افزودن ویژگیهای بیشتر در عرض رشد میکند. شاید مهمترین مزیت ساختار عرضی این باشد که مقادیر ستونها همگن است و میتوان با آنها به عنوان مجموعهای از مقدارهای یکدست یا به بیان دیگر یک بردار برخورد کرد، مثلا مقدارهای یک ستون را جمع کرد یا میانگین گرفت یا ستونی را بر ستون دیگر تقسیم کرد. به عبارت دیگر این ساختار انجام اعمال ریاضی را برای کامپیوتر ممکن میکند و تحلیلگر میتواند با یک فرمان ساده مقدار مورد نظرش را محاسبه کند.
به عنوان مثال، یکی از شاخصهایی که برای سنجش سلامت فرد کاربرد دارد، نسبت کلسترول بد به کلسترول خوب است که برای محاسبه آن میتوان به سادگی ستون کلسترول بد را به ستون کلسترول خوب به صورت نظیر به نظیر تقسیم کرد. این دستور برای کامپیوتر خوشتعریف و قابل فهم است.
اگر بخواهیم روند تغییرات هر یک از ویژگیها را مشاهده کنیم نیز میتوانیم تنها با فراخوانی ستون مربوطه آن را روی نمودار ببریم و روند تغییرات را مشاهده کنیم.

ساختار طولی (Long Format)
در مقابل ساختار عرضی یک ساختار طولی برای سازماندهی دادهها در جداول نیز وجود دارد. در ساختار طولی، با افزودن تعداد ویژگیها، جدول در عرض رشد نمیکند بلکه به تعداد سطرهای آن اضافه میشود و در طول رشد میکند یا اصطلاحاً دراز میشود. اگر همین دادههایی که برای نتایج آزمایشهای خون گردآوری کرده بودیم را در ساختار طولی سازماندهی کنیم نتیجه به صورت زیر میشود:
| تاریخ | ویژگی | مقدار |
| 1392/12/03 | هموگلوبین | 17.1 |
| 1392/12/03 | تعداد گلبولهای سفید | 7.8 |
| 1392/12/03 | تعداد گلبولهای قرمز | 5.4 |
| 1392/12/03 | کلسترول خوب | 44 |
| 1392/12/03 | کلسترول بد | 110 |
| 1394/05/21 | هموگلوبین | 16.4 |
| 1394/05/21 | تعداد گلبولهای سفید | 7.3 |
| 1394/05/21 | تعداد گلبولهای قرمز | 5.1 |
| 1394/05/21 | کلسترول خوب | 42 |
| 1394/05/21 | کلسترول بد | 112 |
| 1395/08/02 | هموگلوبین | 16.9 |
| 1395/08/02 | تعداد گلبولهای سفید | 7.1 |
| 1395/08/02 | تعداد گلبولهای قرمز | 5.5 |
| 1395/08/02 | کلسترول خوب | 45 |
| 1395/08/02 | کلسترول بد | 113 |
| 1398/07/15 | هموگلوبین | 17.7 |
| 1398/07/15 | تعداد گلبولهای سفید | 7.6 |
| 1398/07/15 | تعداد گلبولهای قرمز | 5.4 |
| 1398/07/15 | کلسترول خوب | 47 |
| 1398/07/15 | کلسترول بد | 118 |
| 1400/02/27 | هموگلوبین | 18.5 |
| 1400/02/27 | تعداد گلبولهای سفید | 8.2 |
| 1400/02/27 | تعداد گلبولهای قرمز | 5.9 |
| 1400/02/27 | کلسترول خوب | 46 |
| 1400/02/27 | کلسترول بد | 114 |
| 1401/05/18 | هموگلوبین | 17.9 |
| 1401/05/18 | تعداد گلبولهای سفید | 8.1 |
| 1401/05/18 | تعداد گلبولهای قرمز | 6.1 |
| 1401/05/18 | کلسترول خوب | 45 |
| 1401/05/18 | کلسترول بد | 118 |
این جدول عینا همان دادههایی را که در ساختار عرضی ارائه شده بود در بر میگیرد. در ساختار طولی به جای اینکه مقدارها در ساختاری شبیه ماتریس ذخیره شوند، در طول یک ستون مرتب میشوند. در جدول فوق که با ساختار طولی تنظیم شده، شناسۀ مشاهدات (تاریخ) و نام هر یک از ویژگیها تکرار شدهاند تا پیدا کردن هر یک از مقدارها از طریق آنها امکانپذیر باشد.
در ساختار طولی هم میتوانیم هر سطر را به عنوان یک مشاهده در نظر بگیریم، اگرچه تمام مشاهدات در آن مانند ساختار عرضی از یک جنس نیستند.
فیلتر کردن جدول
ساختار طولی نیز مشابه ساختار عرضی منطق مشخص و سادهای برای فراخوانی مقدارها دارد. به همین دلیل پردازش و تحلیل آن به خوبی امکانپذیر است. مثلا اگر بخواهیم ببینیم در تاریخ 1398/07/15، تعداد گلبولهای سفید چقدر بوده کافی است جدول را در ستونهای مربوطه اصطلاحاً روی این موارد فیلتر کنیم. منظور از فیلتر کردن جدول روی این موارد این است که سطرهایی از جدول را فراخوانی کنیم که در آنها مقدار ستون تاریخ برابر 1398/07/15 و مقدار ستون ویژگی برابر تعداد گلبولهای سفید باشد تا به مقدار مورد نظر خود دست یابیم.

تلفیق ساختار طولی و عرضی
بسیاری از جداولی که با آنها سر و کار داریم در حقیقت تلفیقی از ساختار طولی و ساختار عرضی هستند. به عنوان مثال فرض کنید به جای نتایج آزمایش یک نفر، نتایج آزمایش سه نفر را در اختیار داریم: شخص A و B و C. اگر بخواهیم دادههای این سه نفر را در یک جدول داشته باشیم، علاوه بر استفاده از ساختارهای طولی و عرضی، یکی از روشهای پرکاربرد در پردازش و تحلیل داده این است که با تکرار نامها در هر سطر از تلفیقی از ساختار طولی و عرضی به صورت زیر استفاده کنیم.
| نام | تاریخ | هموگلوبین | تعداد گلبولهای سفید | تعداد گلبولهای قرمز | کلسترول خوب | کلسترول بد |
| A | 1392/12/03 | 17.1 | 7.8 | 5.4 | 44 | 110 |
| A | 1394/05/21 | 16.4 | 7.3 | 5.1 | 42 | 112 |
| A | 1395/08/02 | 16.9 | 7.1 | 5.5 | 45 | 113 |
| A | 1398/07/15 | 17.7 | 7.6 | 5.4 | 47 | 118 |
| A | 1400/02/27 | 18.5 | 8.2 | 5.9 | 46 | 114 |
| A | 1401/05/18 | 17.9 | 8.1 | 6.1 | 45 | 118 |
| B | 1391/02/14 | 16.1 | 7.1 | 6 | 48 | 108 |
| B | 1393/11/12 | 15.9 | 6.9 | 5 | 49 | 110 |
| B | 1394/07/13 | 16.4 | 6.9 | 5.1 | 41 | 112 |
| B | 1399/09/18 | 17 | 7.3 | 5.2 | 4.2 | 110 |
| B | 1400/01/19 | 18.5 | 8.1 | 5.7 | 49 | 119 |
| B | 1400/05/27 | 17.1 | 7.9 | 5.1 | 46 | 114 |
| B | 1401/03/12 | 17.9 | 8.1 | 6 | 44 | 108 |
| B | 1401/04/01 | 17.4 | 8 | 6 | 41 | 115 |
| C | 1392/07/12 | 16.7 | 7.3 | 5.2 | 41 | 108 |
| C | 1396/05/23 | 16.2 | 7.1 | 5 | 40 | 110 |
| C | 1398/07/14 | 17.3 | 7.7 | 5.1 | 49 | 101 |
چنانچه مشاهده میکنید تعداد مشاهدات مربوط به هر یک از نفرات در جدول بالا برابر نیست. با این حال این تفاوت اشکالی در شیوه ذخیره کردن دادهها در جدول ایجاد نکرده است. در این ساختار اگر لازم باشد میتوانیم ویژگیهای اشخاص مانند سن و جنسیت آنها را هم مشابه نام آنها در سطرها تکرار و به جدول اضافه کنیم.
| نام | جنسیت | سال تولد | تاریخ | هموگلوبین | تعداد گلبولهای سفید | تعداد گلبولهای قرمز | کلسترول خوب | کلسترول بد |
| A | مذکر | 1374 | 1392/12/03 | 17.1 | 7.8 | 5.4 | 44 | 110 |
| A | مذکر | 1374 | 1394/05/21 | 16.4 | 7.3 | 5.1 | 42 | 112 |
| A | مذکر | 1374 | 1395/08/02 | 16.9 | 7.1 | 5.5 | 45 | 113 |
| A | مذکر | 1374 | 1398/07/15 | 17.7 | 7.6 | 5.4 | 47 | 118 |
| A | مذکر | 1374 | 1400/02/27 | 18.5 | 8.2 | 5.9 | 46 | 114 |
| A | مذکر | 1374 | 1401/05/18 | 17.9 | 8.1 | 6.1 | 45 | 118 |
| B | مونث | 1358 | 1391/02/14 | 16.1 | 7.1 | 6 | 48 | 108 |
| B | مونث | 1358 | 1393/11/12 | 15.9 | 6.9 | 5 | 49 | 110 |
| B | مونث | 1358 | 1394/07/13 | 16.4 | 6.9 | 5.1 | 41 | 112 |
| B | مونث | 1358 | 1399/09/18 | 17 | 7.3 | 5.2 | 4.2 | 110 |
| B | مونث | 1358 | 1400/01/19 | 18.5 | 8.1 | 5.7 | 49 | 119 |
| B | مونث | 1358 | 1400/05/27 | 17.1 | 7.9 | 5.1 | 46 | 114 |
| B | مونث | 1358 | 1401/03/12 | 17.9 | 8.1 | 6 | 44 | 108 |
| B | مونث | 1358 | 1401/04/01 | 17.4 | 8 | 6 | 41 | 115 |
| C | مذکر | 1369 | 1392/07/12 | 16.7 | 7.3 | 5.2 | 41 | 108 |
| C | مذکر | 1369 | 1396/05/23 | 16.2 | 7.1 | 5 | 40 | 110 |
| C | مذکر | 1369 | 1398/07/14 | 17.3 | 7.7 | 5.1 | 49 | 101 |
این ساختار جدول بالا را به مجموعهای از ویژگیها که در سطرها تکرار میشوند (۴ ستون اول) و مجموعهای شاخصها (۵ ستون آخر) برای توصیف هر یک از مشاهدات تقسیم میکند. در ادبیات هوش تجاری (Business Intelligence) که برای مدیریت و تحلیل داده در کسبوکارها و سازمانها مورد استفاده قرار میگیرد، به ویژگیها بُعد (Dimension) و به شاخصها اندازه (Measure) نیز گفته میشود.
خلاصه
در این درس دیدیم چگونه دادههایی را که برای بررسی لازم داریم، در قالب یک جدول سازماندهی کنیم. برای این کار لازم است مشخص کنیم چه چیزی را به عنوان یک مشاهده در نظر میگیریم و چه ویژگیها یا متغیرهایی را در ارتباط با آن میخواهیم ثبت کنیم. در ضمن با ساختار عرضی و ساختار طولی و تلفیقی از هر دو برای ذخیره و نگهداری دادهها در قالب جدول آشنا شدیم.